Faking It!
Social media has become the primary source of news for their users. Besides fostering social connections between persons, social networks also represent the ideal environment for undesirable phenomena, such as the dissemination of unwanted or aggressive content, misinformation and fake news, which all affect the individuals as well as the society as a whole. Thereby, in the last few years, the research on misinformation has received increasing attention. Nonetheless, even though some computational solutions have been presented, the lack of a common ground and public datasets has become one of the major barriers. Not only datasets are rare, but also, they are mostly limited to only the actual shared text, neglecting the importance of other features, such as social content and temporal information. In this scenario, this project proposes the creation of a publicly available dataset, comprising multi-sourced data and including diverse features related not only to the textual and multimedia content, but also to the social context of news and their temporal information. This dataset would not only allow tackling the task of fake news detection, but also studying their evolution, which, in turn, can foster the development of mitigation and debunking techniques.
The Figure shows the diffent types of data that can be retrived using Faking It!.
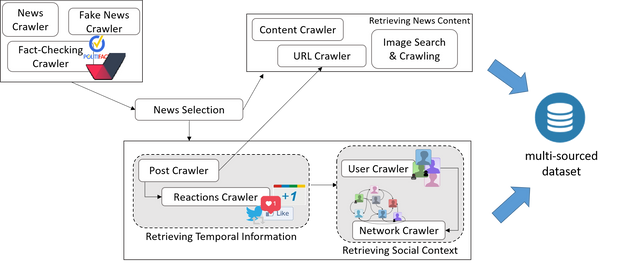
In summary, Faking It! allows to collect:
- Web content retrieved from urls given as input.
- Social posts referring to the selected news.
- Temporal diffusion of posts trajectory (for example, retweet or replies chains).
- URL and images accompanying the retrieved posts.
- For each user engaged in the diffusion process, the profile, posts and social network.
The original aim of the tool was collecting datasets related to the evolution and propagation of fake news. In this context, the collected multi-source datasets have the potential to contribute in the study of various open research problems related to fake news. The augmented set of features provides a unique opportunity to play with different techniques for detecting and analysing the evolution of fake news. Moreover, the temporal information enables the study of the processes of fake news diffusion and evolution, and the roles that users play in such processes through social media reactions. The proposed dataset could be the starting point of diverse exploratory studies and potential applications:
-
Fake news detection. One of the main difficulties is the lack of reliable labelled data and an extended feature set. The presented dataset aims at providing reliable labels annotated by humans and multi-sourced features including text, images, social context and temporal information.
-
Fake news evolution and engagement cycle. The diffusion process involves different stages in users’ engagement and reaction. Using the temporal information could help to study how stories become viral and their diffusion trajectories across social media. This would also allow to study the roles that users play on the diffusion.
-
Fake and malicious account detection. These types of accounts include social bots, trolls and spammers, which can all boost the spread of fake news. The user features in the dataset would allow studying the characteristics of such type of users, how they differentiate from legitimate users and how they contribute to the spread of disinformation.
-
Fake news debunking. Knowing the evolution and trajectories of fake news could help in the study of the debunking process. Likewise, user reactions and answers in social media can provide useful elements to help to determine the veracity of a piece of news.
Antonela Tommasel
Assistant Professor at JKU and researcher at CONICET
My research interests include social computing applications of machine learning and recommender systems.